ACSL Interpreter
Fully functional parser, interpreter, and debugger for the pseudo-code language invented by ACSL.
In high school, I participated in an year-wide competition called American Computer Science League (ACSL). ACSL competitions test participants on a variety of computer science topics like boolean algebra, graph theory, and assembly. One topic that participants are quizzed on is called “What Does This Program Do”. Students are given a program in a fictitious programming language that strongly resembles Python or Ruby. They designed it this way probably so people couldn’t just cheat by running the program.
I thought it would be funny if I made it so you can actually run their programs.
Features
These are the full capabilities of the language as defined by the ACSL wiki
| Construct | Code Segment |
|---|---|
| Operators | ! (not), ^ or ↑(exponent), *, / (real division), % (modulus), +, -, >, <, >=, <=, !=, ==, && (and), || (or) in that order of precedence |
| Functions | abs(x) - absolute value, sqrt(x) - square root, int(x) - greatest integer <= x |
| Variables | Start with a letter, only letters and digits |
| Sequential statements | INPUT variablevariable = expression (assignment) OUTPUT variable |
| Decision statements | IF boolean expression THENStatement(s) ELSE (optional)Statement(s) END IF |
| Indefinite Loop statements | WHILE boolean expressionStatement(s) END WHILE |
| Definite Loop statements | FOR variable = start TO end STEP incrementStatement(s) NEXT |
| Arrays: | 1 dimensional arrays use a single subscript such as A(5). 2 dimensional arrays use (row, col) order such as A(2,3). Arrays can start at location 0 for 1 dimensional arrays and location (0,0) for 2 dimensional arrays. Most ACSL past problems start with either A(1) or A(1,1). The size of the array will usually be specified in the problem statement. |
| Strings: | Basically python strings |
And here’s more features found in practice problems that they failed to mention in their wiki:
| Construct | Code Segment |
|---|---|
| Alternate Decision Statement Syntax | IF expression THEN Statement ELSE Statement(one line) |
| Program Early Termination | END |
Basic Theory on Interpreters
I know if you’re using this tool, odds are you are a high school student (or younger!) doing ACSL. Here’s a quick description on how this program works so hopefully I can inspire you to be more interested in programming languages because IMO they’re extremely extremely cool.
This program goes through three phases to turn raw code text into a program:
- Lexing
- Parsing
- Interpreting
Lexer
Strings are an array of characters. To a computer, the string "fortnite" looks
like this: ['f', 'o', 'r', 't', 'n', 'i', 't', 'e']. Our code in its raw form
looks like that too. We can turn it into a more usable form by lexing/tokenizing
it. Instead of having an array of characters, we can have an array of “tokens”
instead.
For example, the tokenization of int varName = 30 + func(3); is:
['int', 'varName', '=', '30', '+', 'func', '(', '3', ')']
You can think of it kind of like doing string.split(" ") on our code, but
there’s a little more to it than that. For example, note how it split up
func(3) into 4 separate tokens.
Additionally, each token is labelled. We know that the int token is a type,
varName is a variable name, and 30 is a string literal.
Parser
The parser turns the list of tokens into structures of code. In our code, if you
see the pattern type variableName = value, you know that this is an
assignment.
The parser will look for these patterns and turn them into something called an Abstract Syntax Tree (AST).

ANTLR and Backus-Normal Form Notation
I didn’t write the lexer or parser myself. I used a program called ANTLR that generates the code for the lexer and parser if I give it a file that describes the programming language I want to parse.
(Most) programming languages can be described using mathematical expressions. I wrote a description of the language I wanted to parse using those expressions, gave it to ANTLR, and ANTLR wrote the code for me.
Here’s an excerpt that describes an assignment and a for loop:
assignment: (id | array_reference) '=' expression; // A = "value" or A[3] = "value"
for_loop_stmt:
'FOR' assignment 'TO' expression ('STEP' expression)? // The STEP is optional
stmt_list
'NEXT';
You can find the grammar definition file for ACSL pseudo-code here.
Interpreter
Funnily enough, the purpose of “What Does This Program Do” questions is to train your brain to think like the interpreter. You already know how the interpreter works.
There are two main parts to the interpreter: evaluating expressions and control logic.
Evaluating Expressions
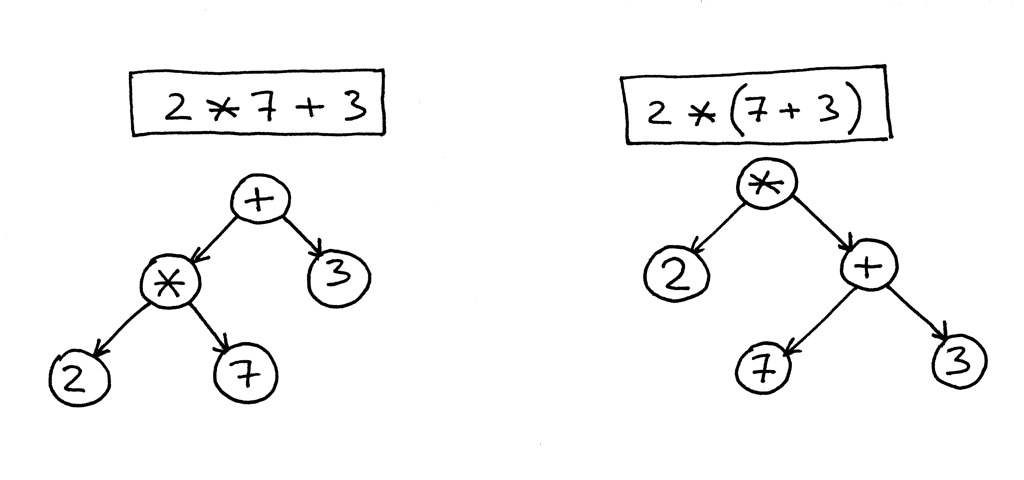
Expressions in the AST might look like this. Evaluating these is straightforward - evaluate the bottom nodes first and work your way up. If one of the nodes is a reference to a variable, it will have to look up the variable’s value. Nodes can also be a function call, and it will have to execute the function to find its value.
Control Logic
There are no surprises here. Statements are executed exactly as you would expect. For example:
for J = 0 to 10 step 2
[ Some code here ]
next
The for loop is broken up into 4 parts: the initialization assignment J = 0,
the end condition 10, the step amount 2, and the body of the for loop.
- First, it has to find the direction of the for loop. The loop condition of
for J = 0 to 10is implicitlyJ <= 10, but the loop condition offor J = 10 to 0 step -1is implicitlyJ >= 0. Note how the comparison changed from<=to>=. - Next, it checks loop condition. If it’s true, we proceed to step 3, otherwise stop.
- Execute the body of the for loop.
- Increment/decrement the loop variable by executing
J = J + STEP. - Loop back to 2.
Like I said, nothing surprising.
Why ACSL’s Pseudocode is a Terrible Language
The language is clearly supposed to be some dialect of BASIC. Because of that, it inherited some very odd language characteristics from the BASIC family which really irk me.
Case Insensitive Variables
The ACSL wiki page describing the language has this piece of code as an example:
for J = len(A) - 1 to 0 step - 1
T = T + A[j]
next
In this example, the J variable is declared as upper case J but used in the
loop as lower case j, which shows that this language has case-insensitive
variable names.
Why, in my opinion, programming languages should be case-sensitive:
- Forces the programmer to be very deliberate with code.
- Very important for math and physics where different cases of the same
character are often mixed (eg
Vis volume andvis velocity) - When you define a variable, you can encode meta-information through casing (ex camelCase vs PascalCase)
At first, I thought this was a typo. There are so many typos scattered throughout the code examples and the language spec doesn’t say anything about being case-insensitive. After a Google search, it turns out that this was actually intended.
I grew up in a world of case-sensitive languages like Java and Python. I recently picked up Golang which finds the casing of variable names so essential that proper PascalCase and camelCase usage is enforced by the compiler. To me, case-sensitivity is just the way programming languages are supposed to be. That’s all I’ve ever known. Now, apparently, case sensitivity is not as universal as I thought.

There is a clear point in time when the standard shifted from insensitive to sensitive.
Nim is the only exception I can find of a very modern language that’s case-insensitive. Nim actually takes it a few steps further by not differentiating between camel case and snake case (thisVarNameis equivalent tothis_var_namein Nim). Then, they take it a step further by making only the first character case-sensitive. Nim is a real freak. You can read their justification here.
Functions vs Arrays Ambiguity
Another irk I have with this language is how functions calls and arrays have the
same notation - funcName(params...) vs arrayName(i, j, ...). This makes it
impossible to define a grammar that automatically distinguishes the two. In an
ideal world, once I parse code, I should be able to differentiate the two
because they have different AST node types, so it’s clear how they should be
resolved.
How I Solved This Problem
I first solved this by making function names reserved-words. The language
specification on this page says there are exactly 4 functions - int, sqrt,
abs, and len. I changed the grammar to this:
start: function_call | array_reference
function_call: function_name '(' expression* ')';
function_name: ABS | INT_FUNC | SQRT | LEN;
array_reference: id '(' expression (',' expression)* ')';
When it tries to parse, if the name does not match one of the tokens in
function_name, it would fall back by assuming it is an array reference.
This solution works, but I’m not satisfied with it. I shouldn’t have to change the grammar every time I want to add a function to my language. I wanted to solve this in a better way.
How Microsoft Solved This Problem
I have no idea.
Visual Basic has this exact same problem. VB’s procedures and arrays have the
syntax Array(index1, index2, ...) and Procedure(args...) too. Luckily,
Microsoft published the official grammar for Visual Basic
here, so by referencing
it, I should be able to use the same structure in my grammar, too, right? Their
grammar for differentiating arrays and procedures looks like this:
Expression
: SimpleExpression
| TypeExpression
| ...
| InvocationExpression // Procedure Calls
| IndexExpression // Array access
| ...
;
InvocationExpression: Expression ( '(' ArgumentList ')' )?;
IndexExpression: Expression '(' ArgumentList ')';
I studied their grammar for a while and I couldn’t figure out how they got it to
work. These rules are indirect left-recursive, which ANTLR explicitly can’t
parse due to the limitations of how it was implemented. Microsoft published the
grammar as an ANTLR grammar for some reason, which makes things even more
bizarre. Additionally, InvocationExpression will always shadow
IndexExpression, so I don’t see how this could work in any parser.
How I Solved This Problem (Again)
I made my parser two-pass.
On the first pass, it won’t try to distinguish arrays vs functions. It will leave it ambiguous in the AST.
function_or_array = id '(' arguments* ')'
On the second pass, it will traverse the AST and build a symbol table of every
declared variable. Once it encounters a function_or_array node, it will try to
resolve it using the symbol table. If an array was declared with the same name,
it assumes it to be an array. Otherwise, at execution, it will try to resolve
the function from the environment.
The Language Flexibility Downgrade
Based on the language specification, this language could completely ignore whitespace and new-line characters. Additionally, the start and end of statements are inherently unambiguous even without a delimiter such as a semicolon.
But…
The language specification does not mention a secret second form for if statements:
IF condition THEN statement // (One line)
If statements should be delimited by the END IF token, except in this one
case. If we were to ignore new-line characters, we could not tell the difference
between
IF condition1 THEN
IF condition2 THEN statement1
statement2
END IF
and
IF condition1 THEN (IF condition2 THEN (statement1 statement2) ENDIF)
I had to rewrite my grammar to make the language new-line sensitive because of this one single edge case.
This really isn’t a complaint of the language itself. I actually like languages that enforce good layout (like python), but as a developer it was just annoying.
Why is it This Way?
According to random people on StackOverflow and Quora, BASIC was
case-insensitive, and it used () for both arrays and functions because
hardware limitations at the time (we’re talking punch cards). BASIC’s character
set wasn’t large enough to include both upper-case and lower-case letters, and
its character set didn’t even have [], so it used () for everything.
This makes sense, and it’s pretty interesting - but ACSL’s pseudocode doesn’t even follow this logic.
- Using ASCII is acceptable, but then it betrays its restricted-charset history
by using Unicode tokens like
↑. - It uses brackets for string index access anyway. So why not let arrays use brackets too?
As for the trouble with newlines, BASIC was famously designed to be line based.
Weird Spacing
Another example of the actual problems having new syntax rules is how operators in expressions are allowed to have spacing in them. For example:
// These are syntactically equivalent
1 == 1 // True
1 = = 1 // True
This was rather easy to solve, though. Normally in your grammar, you would have
two separate tokens EQ: = and EQEQ: ==. To fix this, I redefined EQEQ in
terms of EQ allowing whitespace - EQEQ: EQ [ ]* EQ