Why RLMs Work So Well
A few weeks ago, some brilliant people from MIT CSAIL proposed a new agent architecture with a very compelling premise: RLMs.
Chroma formalized and measured our collective observation of Context Rot — the property of LLMs where despite their very long context windows, they seem to have a limited attention budget and can only accurately recall things from their context in the 20-100k most recent tokens.
RLMs attempt to solve this problem. The author puts it in words better than I can:
The natural solution is something along the lines of, “well maybe if I split the context into two model calls, then combine them in a third model call, I’d avoid this degradation issue”.
I wanted to see how far I could take RLMs. I don't have access to the OOLONG benchmark, so I decided to skip straight to the more interesting "Ridiculously Large Contexts" BrowseComp-Plus benchmark. I ran my agent on a random subset of 60 questions from the benchmark using the same methodology described in the original blog post.
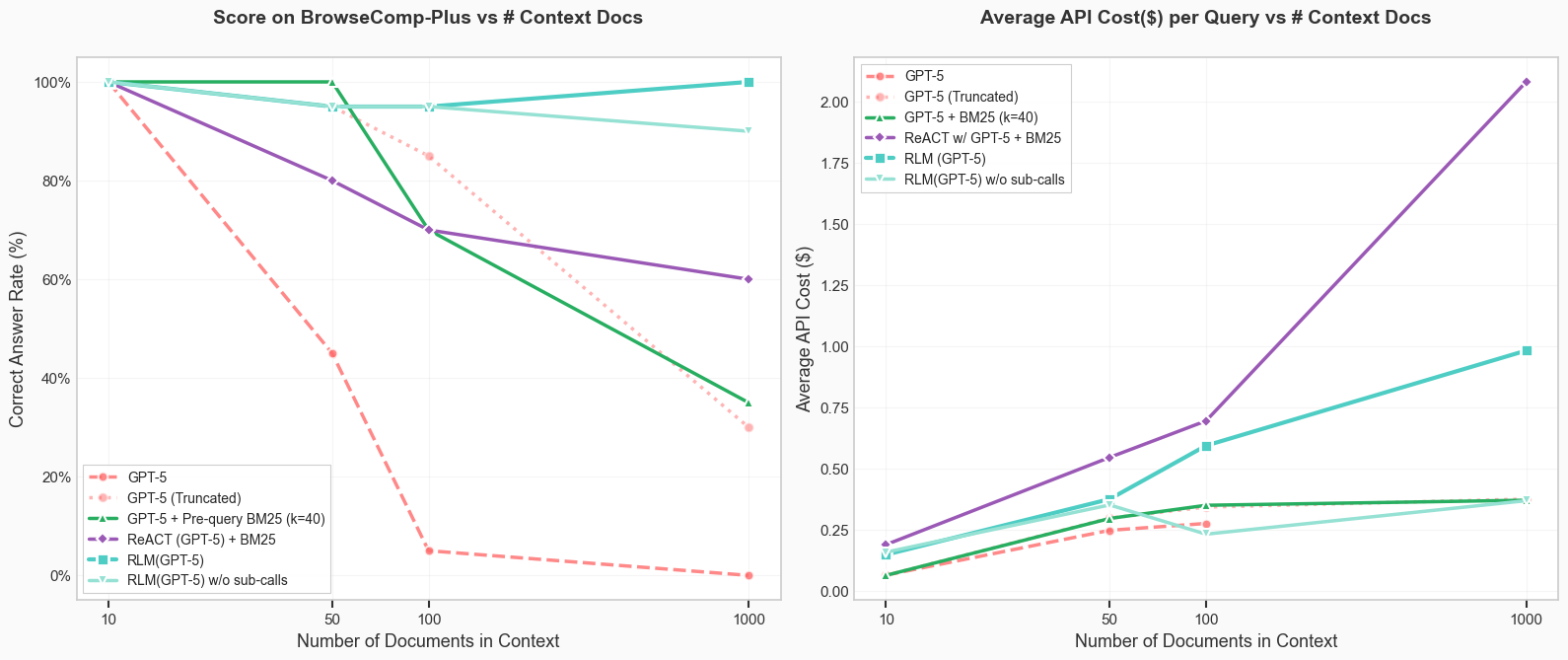
I made an implementation of an RLM that had around the same performance, but far cheaper. I open sourced my implementation here.
Breakdown
RLMs write code in order to query their context and invoke sub-RLMs. This is what most of the code outputted looked like in my implementation:
import re
def format_match_output(key, matches):
header = f"{key}: {len(matches)} matches"
lines = []
for i, pos, snip in matches[:5]:
lines.append(f" doc {i}, pos {pos}: ...{snip}...")
if len(matches) > 5:
lines.append(" ...")
return "\n".join([header] + lines)
def find_matches(pattern):
results = []
for i, doc in enumerate(context):
for m in re.finditer(pattern, doc, flags=re.IGNORECASE):
start = max(0, m.start()-120)
end = min(len(doc), m.end()+120)
snippet = doc[start:end].replace('\n',' ')[:300]
results.append((i, m.start(), snippet))
return results
queries = {
'trolled': r'\btroll(?:ed|ing)?\b',
'ugly': r'\bugly\b',
'old_school_senior': r'old school senior',
'began_dating_22': r'\b(age of 22|at 22|began dating at the age of 22)\b',
'born_in_US': r'born in the United States|US-born|born in the US',
'investment_company': r'investment company',
'dreamt_America': r'dream(?:t|ed) about living in America',
'degree_economics': r'degree in economics',
}
all_matches = {}
for key, pattern in queries.items():
matches = find_matches(pattern)
all_matches[key] = matches
print(format_match_output(key, matches))
It's using regex search to search for key words, and then it prints matches and their surriounding characters out. It's
essentially doing grep -A n -B m.
Another interesting behavior it had was this:
import re
# Step 1: Find documents containing all three rare keywords
hits = [
i for i, doc in enumerate(context)
if re.search(r"nurse", doc, re.I)
and re.search(r"animal rights", doc, re.I)
and re.search(r"film", doc, re.I)
]
print("Candidate docs:", hits[:20])
# Step 2: If no such docs, broaden to documents matching at least 3 rare terms
if not hits:
combos = []
pattern_checks = [
(r"nurse",),
(r"animal rights",),
(r"filmmak|film-making|film making|filmmaking",),
(r"web design",),
(r"piano",),
(r"learned to play from", r"learn(ed)? .* from (his|her|their) (brother|sister|sibling)"),
(r"heads?-up",),
(r"all in",),
(r"remaining (chips|stack).{0,40}(3\d\d,?\\d{3}|[34]\d\d,?\\d{3})",),
]
for i, doc in enumerate(context):
score = 0
for patterns in pattern_checks:
if any(re.search(p, doc, re.I) for p in patterns):
score += 1
if score >= 3:
combos.append((i, score))
combos.sort(key=lambda x: -x[1])
print("Top combo docs (index, score):", combos[:20])
# Step 3: Print snippets of top candidate documents
candidates = hits if hits else [i for i, _ in combos[:5]]
for i in candidates:
snippet = context[i][:1500]
print(f"\n--- Doc {i} snippet ---\n", snippet.replace('\n', ' ')[:1500])
It's reranking the documents by # of matches found.
In addition to this, it would use its code environment to the fullest extent. When given a search query about an event on a day of the week, it used this to help reason about the search space:
[ REPL ]
Reasoning: Let me check the weekday for some suspected premiere dates to validate the Tuesday/Saturday pattern.
import datetime
for d in ["1987-04-06","1988-04-04","1989-10-15","1991-01-01","1983-10-13","1988-10-17"]:
y,m,day=map(int,d.split('-'))
print(d, datetime.date(y,m,day).strftime('%A'))
--------------------------------
[REPL OUTPUT]
1987-04-06 Monday
1988-04-04 Monday
1989-10-15 Sunday
1991-01-01 Tuesday
1983-10-13 Thursday
1988-10-17 Monday
Analysis
My RLM implementation was primarily using its code environment to navigate its context. I counted how many instances it actually used recursion, and it was in only... one test case. I removed all recursive and sub-llm elements from my RLM and its performance was unchanged.
I don't think this discredits the premise of RLMs, it actually gave me a new level of appreciation for it. What it did was functionally equivalent to
chunking a document, using BM25, and using a get_datetime tool. The beauty of my findings
in the previous section is that I didn't have to design the RLM to do this, it did it on its own. When you give an AI agent enough freedom,
it will exhibit emergent behavior like this.
The cool thing about RLMs is that they were able to achieve so much using only a small subset of their capabilities. I can only imagine what my RLM could do if I was able to get it to use its harness to its fullest extent.