Is Mode Collapse Killing Free AI Agents?
Over the past two weeks, I've built ~20 variations of AI "deep research" agents and spent $6,320 of my company's money. I learned that an agent's creativity is the difference between an AI agent being useless versus topping a benchmark. There's something weird going on, and I suspect that RL training on models can negatively impact them.
...
There are two camps in the AI world: rigid AI workflows that heavily restrict and control what LLMs do in order to maximize reliability, and AI agents that give an AI an environment, tools, and freedom.
People have observed that code agents like Claude Code seem to be unreasonably good at search tasks* despite only using primitive search tools like grep — and my informal benchmarks at Chroma agree. But why? When given enough freedom, AI agents exhibit emergent behavior — they begin to use and compose the tools in their environment in creative manners. Despite their lack of structure, this gives them the edge to outperform an ill-optimized "rigid" system.
In code agents specifically, they use their coding environment to the fullest extent to answer search queries. When
I've observed that the capability of AI agents can vary drastically, with minor changes that logically should be equivocal or irrelevant. For example,
I could change the name of a regex search tool from search to grep and performance drops, or I make a tool return a dict instead of a list and get
a similar drop in performance. Why is an LLM's ability to write search queries dependent on these factors?
I noticed that these drops in performance are accompanied with a single code block.
Their exciting emergent behavior would collapse into the soulless repetition of this stringresults = search("...")
print(len(results))
for docid, snippet in results[:20]:
print(docid, snippet[:300].replace('\\n',' '))
Hundreds of agents would independently use this exact same code block to make queries, even when I did not provide any sample code. This seems to be characteristic of GPT-5.
To quantify this, I measured the diversity of code generated by the code agents against their benchmark performance. Each point on the plot represents an agent run on 60 BrowseComp-Plus queries, measuring diversity through two metrics:
- Code embedding distance: Average pairwise cosine distance between code blocks.
- Normalized sequence diversity: Levenshtein distance between code blocks (with variables and literals normalized).
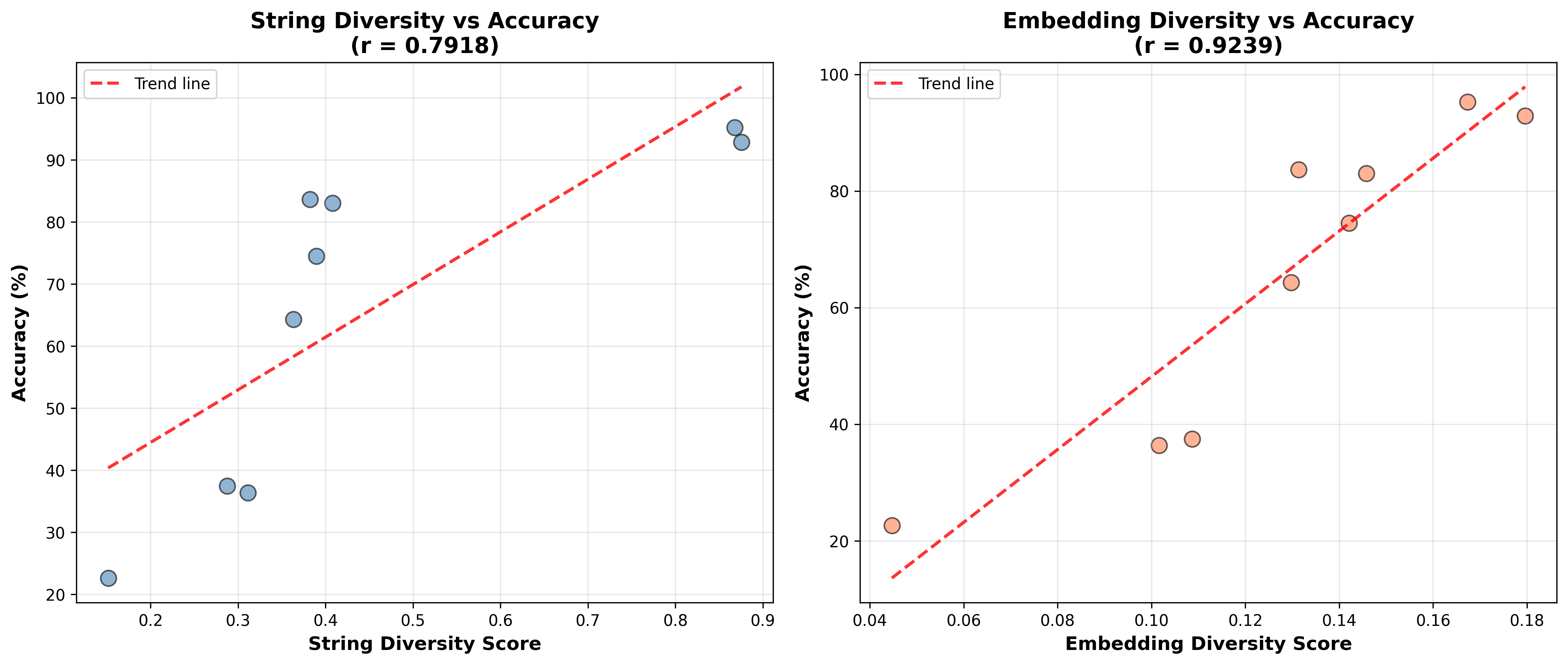
This quick measurement supports my hypothesis.