AI Agent Emergence
Over the past two weeks, I've built ~20 variations of AI agents and spent $6,320 of my company's money. I learned that creativity and emergent behavior are the difference between an AI agent being useless versus topping a benchmark.
People have observed that code agents like Claude Code seem to be unreasonably good at search tasks* despite only using primitive search tools like grep — and my informal benchmarks at Chroma agree. Why?
Cloudflare recently made a post about "Code Mode", where they observed that AI agents appear to perform better at tasks when writing code rather than using tool calls. They hypothesized two reasons:
-
LLMs are largely trained on code, not on tool calls. They are simply better at reasoning and planning when done in the form of code rather than tools.
-
Better composability: In tool mode, the LLM has to:
- Call one tool,
- Wait for the result to come back,
- Re-ingest that result,
- Then call the next tool.
That means extra tokens, latency, and chances for error. In code mode, it just writes
print(summarize(fetch_from_api("..."))). This is faster and more context-efficient.
Assuming this is true, I should be able to get an instant performance boost by converting tool-based agents into code agents, right? I made a few code agents and provided them the exact same search tools given to the tool-based search agents in benchmarks. For example, BrowseComp-Plus gives the agent a search and get_document MCP tool, so I equivalently provided search and get_document Python functions in its environment.
Emergent Behavior in Code Search Agents
Search agents greatly benefit from being able to write and execute code. For example, in one of the tests in the benchmark, the query was asking about an event. The agent was able to use
the datetime package to help it reason.
[ REPL ]
Reasoning: Let me check the weekday for some suspected premiere dates to validate the Tuesday/Saturday pattern.
import datetime
for d in ["1987-04-06","1988-04-04","1989-10-15","1991-01-01","1983-10-13","1988-10-17"]:
y,m,day=map(int,d.split('-'))
print(d, datetime.date(y,m,day).strftime('%A'))
--------------------------------
[REPL OUTPUT]
1987-04-06 Monday
1988-04-04 Monday
1989-10-15 Sunday
1991-01-01 Tuesday
1983-10-13 Thursday
1988-10-17 MondayDespite not being prompted to, code agents tend to stay very context efficient. They peek at documents instead of dumping the whole document in context, and have the tools to be able to extract only the parts of the document that are relevant to the query.
...
# For each hit doc, extract a small snippet around likely keywords to narrow down
snippets = []
for i in hits[:50]:
doc = context[i]
# find 'mission' occurrences
for m in re.finditer(r"mission", doc, re.IGNORECASE):
start = max(0, m.start() - 200)
end = min(len(doc), m.start() + 400)
snippets.append((i, doc[start:end]))
if len(snippets) > 100:
break
...None of this is novel. The first example is equivalent to giving an agent a datetime MCP tool. The second one is equivalent to using small and intelligent chunking for your documents. What makes code agents remarkable is that I did not have to design the system to be able to do this. Code agents have a great amount of freedom in how they solve problems, so solutions like this are inevitable. This is emergent behavior.
Emergent Behavior Improves Performance on Tasks
Depending on the harness and prompt, I noticed that sometimes the code agent would keep using the same code over and over again:
results = search("...")
print(len(results))
for docid, snippet in results[:20]:
print(docid, snippet[:300].replace('\\n',' '))Hundreds of agents would independently use this exact same code snippet, even when I did not provide them sample code. Their emergent behavior would collapse into soulless, rote behavior. I also started associating this behavior with getting bad results on benchmarks.
To quantify this, I measured the diversity of code generated by the code agents against their benchmark performance. Each point on the plot represents an agent run on 60 BrowseComp-Plus queries, measuring diversity through two metrics:
- Code embedding distance: Average pairwise cosine distance between code blocks.
- Normalized sequence diversity: Levenshtein distance between normalized code sequences (with variables and literals normalized).
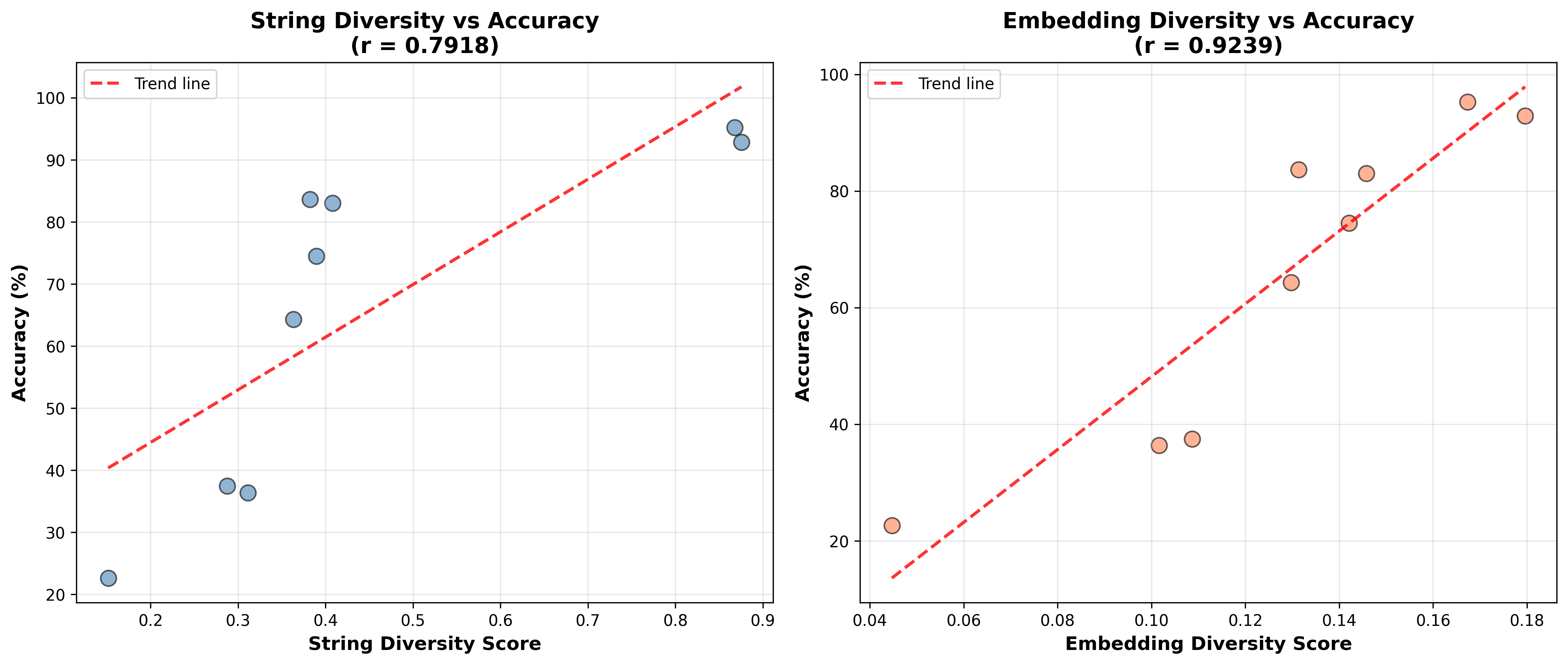
The graph shows a strong positive correlation between code diversity or "creativity" and benchmark performance.
This seemed to occur independent of the size of the corpus, and would change without logic based on changes to the prompt or search tools provided to the agent.
So, how do you prompt an agent to be creative?
We understand that creativity is a combination of the underlying model's weights, RL, the agentic framework, and what's in the context window. We're currently doing a lot of really cool work regarding these kinds of questions — but we're not quite ready to share yet.
This is fundamentally about making an agent intelligently use its tools and framework to the fullest. The best agents are those that can intelligently compose their available tools in novel ways. The agent's harness should facilitate this.